RAPID-OVD
面向复杂开放场景的智能目标检测框架,提出 RAPID-CLIP 分类模块、自适应填充策略与四阶段伪标签优化流程。
研究背景
开放词汇目标检测(Open-Vocabulary Object Detection, OVD)旨在让模型识别训练时从未见过的类别,是目标检测领域的前沿方向。借助 CLIP 等视觉-语言预训练模型的零样本迁移能力,OVD 在自动驾驶、智能监控、工业质检等场景展现出巨大潜力。
然而,现有方法面临三个核心瓶颈:伪标签噪声大导致训练信号不可靠;区域裁剪时细长物体发生严重几何变形;少样本场景下泛化能力急剧下降。RAPID-OVD 针对这三个问题分别提出了对应解决方案。
框架设计
RAPID-OVD 采用端到端设计,在 Faster R-CNN / Mask R-CNN 检测框架上构建了三个核心模块:RAPID-CLIP 分类模块负责特征融合与分类决策,自适应填充策略(APS)解决几何变形问题,四阶段伪标签优化流程系统性地提升标签质量。三个模块协同工作,覆盖了从数据预处理到训练再到推理的完整链路。
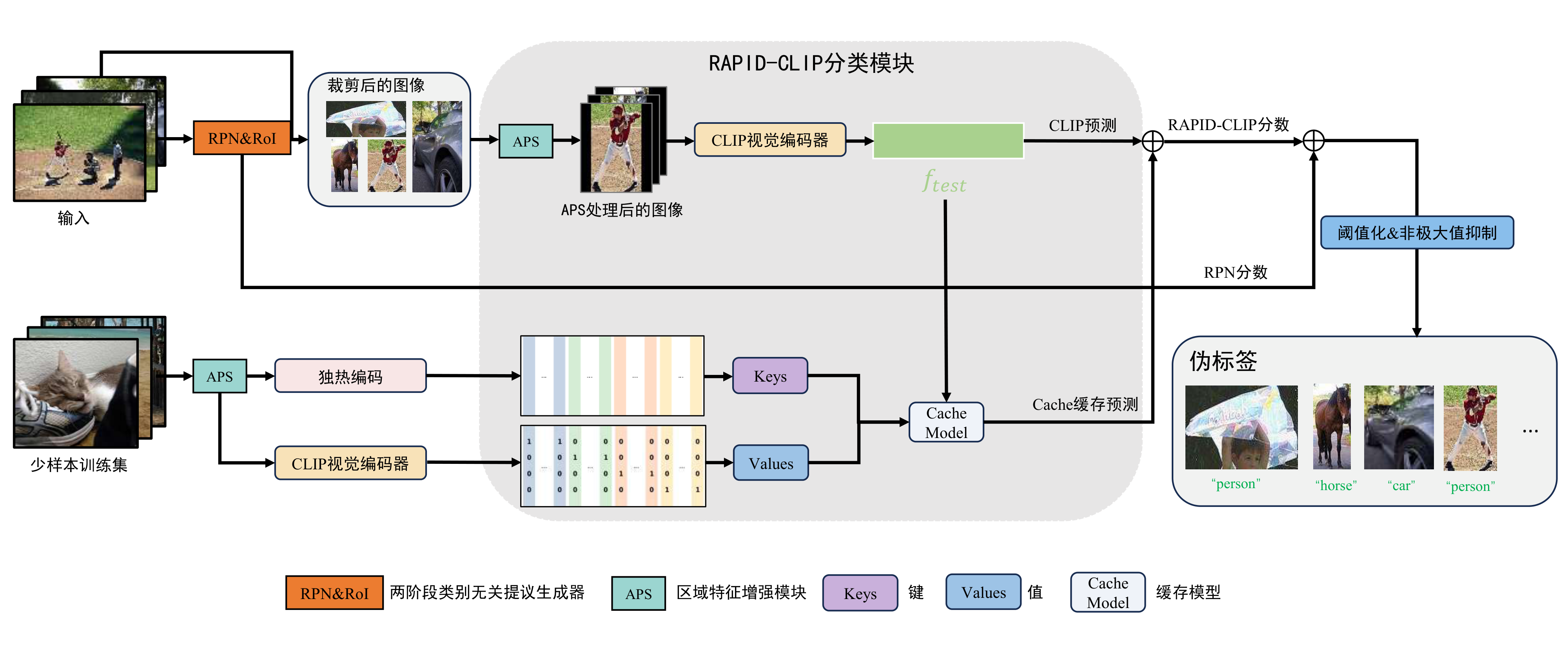
核心模块
RAPID-CLIP 分类模块
基于 CLIP 视觉编码器构建,引入键值缓存(Key-Value Cache)机制。将少样本训练阶段学到的领域知识编码为键值对,推理时与 CLIP 原始预训练知识动态融合。这种设计使得模型仅需 20 轮训练即可逼近 200 轮的分类精度,大幅降低训练成本。
自适应填充策略(APS)
候选区域裁剪是检测流程的标准操作,但对细长物体(如栏杆、电线杆)会造成严重的长宽比失真。APS 根据候选区域的长宽比和面积特征,动态选择最优的上下文填充方式——对于接近正方形的区域直接缩放,对于极端长宽比的区域则保留周围上下文并自适应填充,避免信息丢失。

四阶段伪标签优化
针对伪标签噪声问题设计了系统化的四阶段流程:首先由 RPN 生成候选区域提议,然后通过特征增强模块丰富区域表征,接着利用多源分类器(CLIP + 领域特征)进行类别预测,最后经过 NMS 和置信度阈值双重过滤,输出高质量伪标签用于训练。
实验结果
在 COCO-OVD 和 LVIS 两个主流基准上进行了系统评估。与 VL-PLM(ECCV 2022)、Detic(ECCV 2022)、OV-DQUO(AAAI 2025)等代表性方法对比,RAPID-OVD 在新类别检测精度上取得了显著提升,特别是在细长物体和小物体的检测上优势明显。

上图从上到下依次为 VL-PLM、OV-DQUO 和 RAPID-OVD 的检测结果。可以看到 RAPID-OVD 在检测覆盖率和定位精度方面均有明显改善,尤其是对重叠物体和小目标的召回能力更强。